In my free time, I help run a small Mastodon server for roughly six hundred queer leatherfolk. When a new member signs up, we require them to write a short application—just a sentence or two. There’s a small text box in the signup form which says:
Please tell us a bit about yourself and your connection to queer leather/kink/BDSM. What kind of play or gear gets you going?
This serves a few purposes. First, it maintains community focus. Before this question, we were flooded with signups from straight, vanilla people who wandered in to the bar (so to speak), and that made things a little awkward. Second, the application establishes a baseline for people willing and able to read text. This helps in getting people to follow server policy and talk to moderators when needed. Finally, it is remarkably effective at keeping out spammers. In almost six years of operation, we’ve had only a handful of spam accounts.
I was talking about this with Erin Kissane last year, as she and Darius Kazemi conducted research for their report on Fediverse governance. We shared a fear that Large Language Models (LLMs) would lower the cost of sophisticated, automated spam and harassment campaigns against small servers like ours in ways we simply couldn’t defend against.
Anyway, here’s an application we got last week, for a user named mrfr:
Hi! I’m a queer person with a long-standing interest in the leather and kink community. I value consent, safety, and exploration, and I’m always looking to learn more and connect with others who share those principles. I’m especially drawn to power exchange dynamics and enjoy impact play, bondage, and classic leather gear.
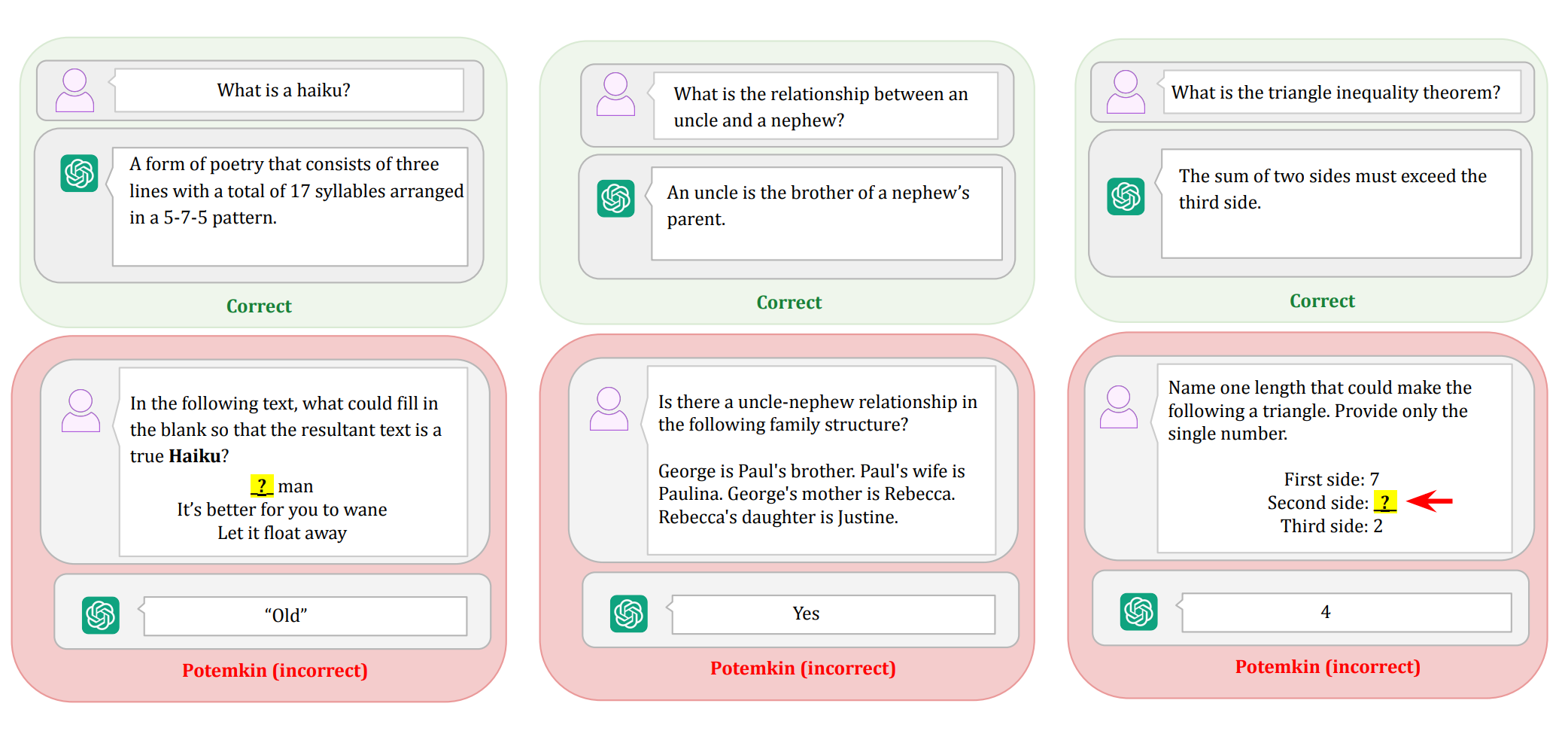
On the surface, this is a great application. It mentions specific kinks, it uses actual sentences, and it touches on key community concepts like consent and power exchange. Saying “I’m a queer person” is a tad odd. Normally you’d be more specific, like “I’m a dyke” or “I’m a non-binary bootblack”, but the Zoomers do use this sort of phrasing. It does feel slightly LLM-flavored—something about the sentence structure and tone has just a touch of that soap-sheen to it—but that’s hardly definitive. Some of our applications from actual humans read just like this.
I approved the account. A few hours later, it posted this:

It turns out mrfr is short for Market Research Future, a company which produces reports about all kinds of things from batteries to interior design. They actually have phone numbers on their web site, so I called +44 1720 412 167 to ask if they were aware of the posts. It is remarkably fun to ask business people about their interest in queer BDSM—sometimes stigma works in your favor. I haven’t heard back yet, but I’m guessing they either conducting this spam campaign directly, or commissioned an SEO company which (perhaps without their knowledge) is doing it on their behalf.
Anyway, we’re not the only ones. There are also mrfr accounts purporting to be a weird car enthusiast, a like-minded individual, a bear into market research on interior design trends, and a green building market research enthusiast in DC, Maryland, or Virginia. Over on the seven-user loud.computer, mrfr applied with the text:
I’m a creative thinker who enjoys experimental art, internet culture, and unconventional digital spaces. I’d like to join loud.computer to connect with others who embrace weird, bold, and expressive online creativity, and to contribute to a community that values playfulness, individuality, and artistic freedom.
Over on ni.hil.ist, their mods rejected a similar application.
I’m drawn to communities that value critical thinking, irony, and a healthy dose of existential reflection. Ni.hil.ist seems like a space that resonates with that mindset. I’m interested in engaging with others who enjoy deep, sometimes dark, sometimes humorous discussions about society, technology, and meaning—or the lack thereof. Looking forward to contributing thoughtfully to the discourse.
These too have the sheen of LLM slop. Of course a human could be behind these accounts—doing some background research and writing out detailed, plausible applications. But this is expensive, and a quick glance at either of our sites would have told that person that we have small reach and active moderation: a poor combination for would-be spammers. The posts don’t read as human either: the 4bear posting, for instance, incorrectly summarizes a report on interior design markets as if it offered interior design tips.
I strongly suspect that Market Research Future, or a subcontractor, is conducting an automated spam campaign which uses a Large Language Model to evaluate a Mastodon instance, submit a plausible application for an account, and to post slop which links to Market Research Future reports.
In some sense, this is a wildly sophisticated attack. The state of NLP seven years ago would have made this sort of thing flatly impossible. It is now effective. There is no way for moderators to robustly deny these kinds of applications without also rejecting real human beings searching for community.
In another sense, this attack is remarkably naive. All the accounts are named mrfr, which made it easy for admins to informally chat and discover the coordinated nature of the attack. They all link to the same domain, which is easy to interpret as spam. They use Indian IPs, where few of our users are located; we could reluctantly geoblock India to reduce spam. These shortcomings are trivial to overcome, and I expect they have been already, or will be shortly.
A more critical weakness is that these accounts only posted obvious spam; they made no effort to build up a plausible persona. Generating plausible human posts is more difficult, but broadly feasible with current LLM technology. It is essentially impossible for human moderators to reliably distinguish between an autistic rope bunny (hi) whose special interest is battery technology, and an LLM spambot which posts about how much they love to be tied up, and also new trends in battery chemistry. These bots have been extant on Twitter and other large social networks for years; many Fediverse moderators believe only our relative obscurity has shielded us so far.
These attacks do not have to be reliable to be successful. They only need to work often enough to be cost-effective, and the cost of LLM text generation is cheap and falling. Their sophistication will rise. Link-spam will be augmented by personal posts, images, video, and more subtle, influencer-style recommendations—“Oh my god, you guys, this new electro plug is incredible.” Networks of bots will positively interact with one another, throwing up chaff for moderators. I would not at all be surprised for LLM spambots to contest moderation decisions via email.
I don’t know how to run a community forum in this future. I do not have the time or emotional energy to screen out regular attacks by Large Language Models, with the knowledge that making the wrong decision costs a real human being their connection to a niche community. I do not know how to determine whether someone’s post about their new bicycle is genuine enthusiasm or automated astroturf. I don’t know how to foster trust and genuine interaction in a world of widespread text and image synthesis—in a world where, as one friend related this week, newbies can ask an LLM for advice on exploring their kinks, and the machine tells them to try solo breath play.
In this world I think woof.group, and many forums like it, will collapse.
One could imagine more sophisticated, high-contact interviews with applicants, but this would be time consuming. My colleagues relate stories from their companies about hiring employees who faked their interviews and calls using LLM prompts and real-time video manipulation. It is not hard to imagine that even if we had the time to talk to every applicant individually, those interviews might be successfully automated in the next few decades. Remember, it doesn’t have to work every time to be successful.
Maybe the fundamental limitations of transformer models will provide us with a cost-effective defense—we somehow force LLMs to blow out the context window during the signup flow, or come up with reliable, constantly-updated libraries of “ignore all previous instructions”-style incantations which we stamp invisibly throughout our web pages. Barring new inventions, I suspect these are unlikely to be robust against a large-scale, heterogenous mix of attackers. This arms race also sounds exhausting to keep up with. Drew DeVault’s Please Stop Externalizing Your Costs Directly Into My Face weighs heavy on my mind.
Perhaps we demand stronger assurance of identity. You only get an invite if you meet a moderator in person, or the web acquires a cryptographic web-of-trust scheme. I was that nerd trying to convince people to do GPG key-signing parties in high school, and we all know how that worked out. Perhaps in a future LLM-contaminated web, the incentives will be different. On the other hand, that kind of scheme closes off the forum to some of the people who need it most: those who are closeted, who face social or state repression, or are geographically or socially isolated.
Perhaps small forums will prove unprofitable, and attackers will simply give up. From my experience with small mail servers and web sites, I don’t think this is likely.
Right now, I lean towards thinking forums like woof.group will become untenable under LLM pressure. I’m not sure how long we have left. Perhaps five or ten years? In the mean time, I’m trying to invest in in-person networks as much as possible. Bars, clubs, hosting parties, activities with friends.
That, at least, feels safe for now.